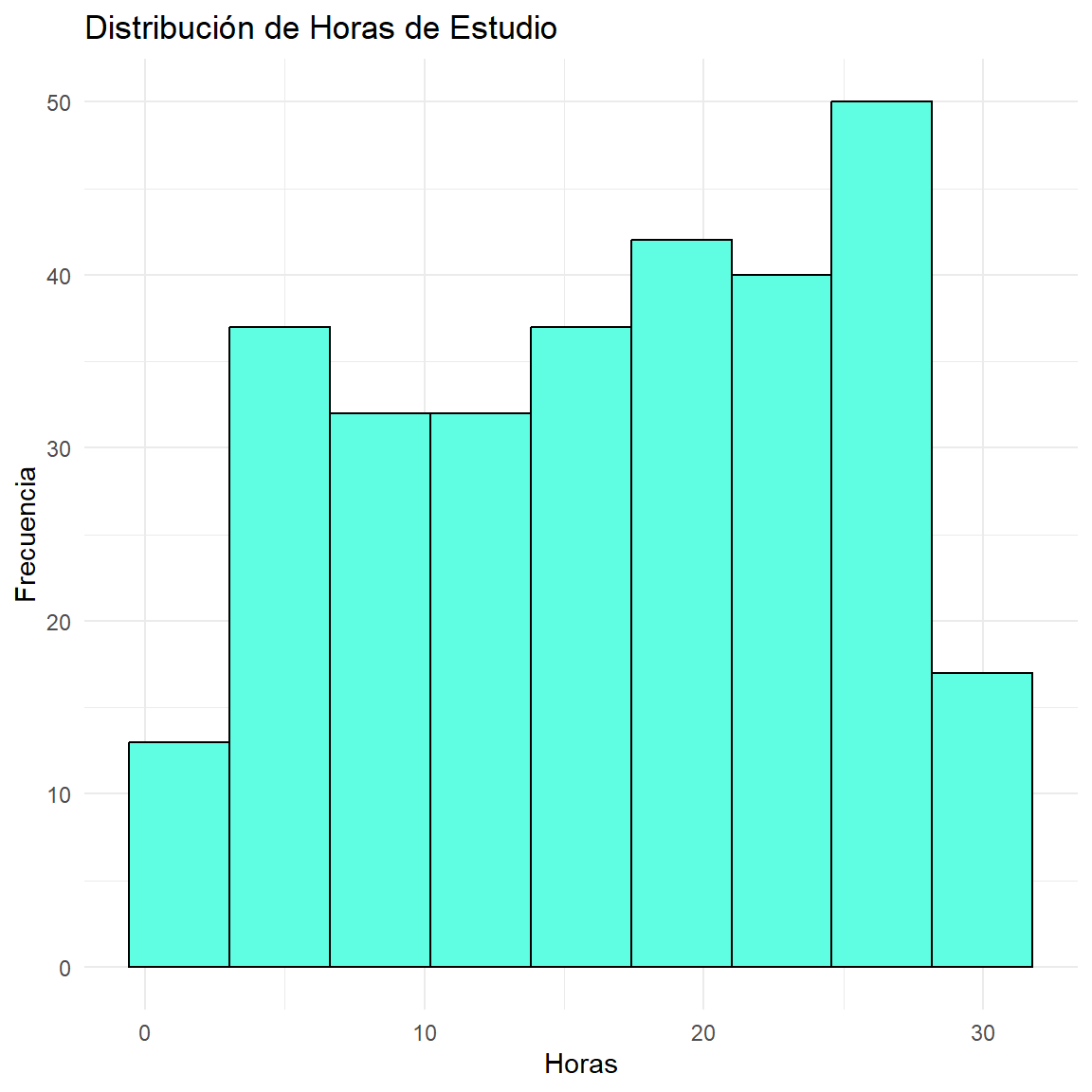
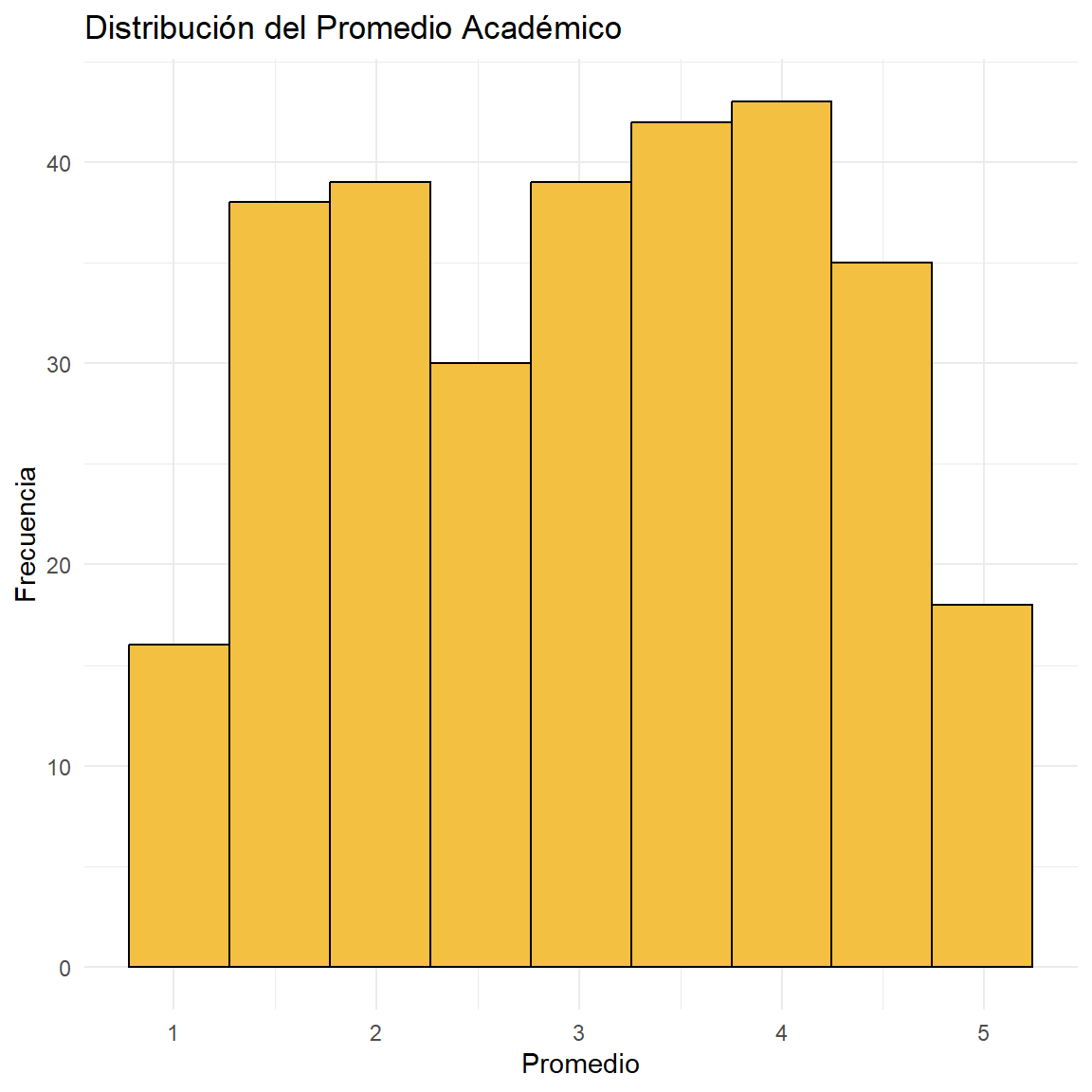
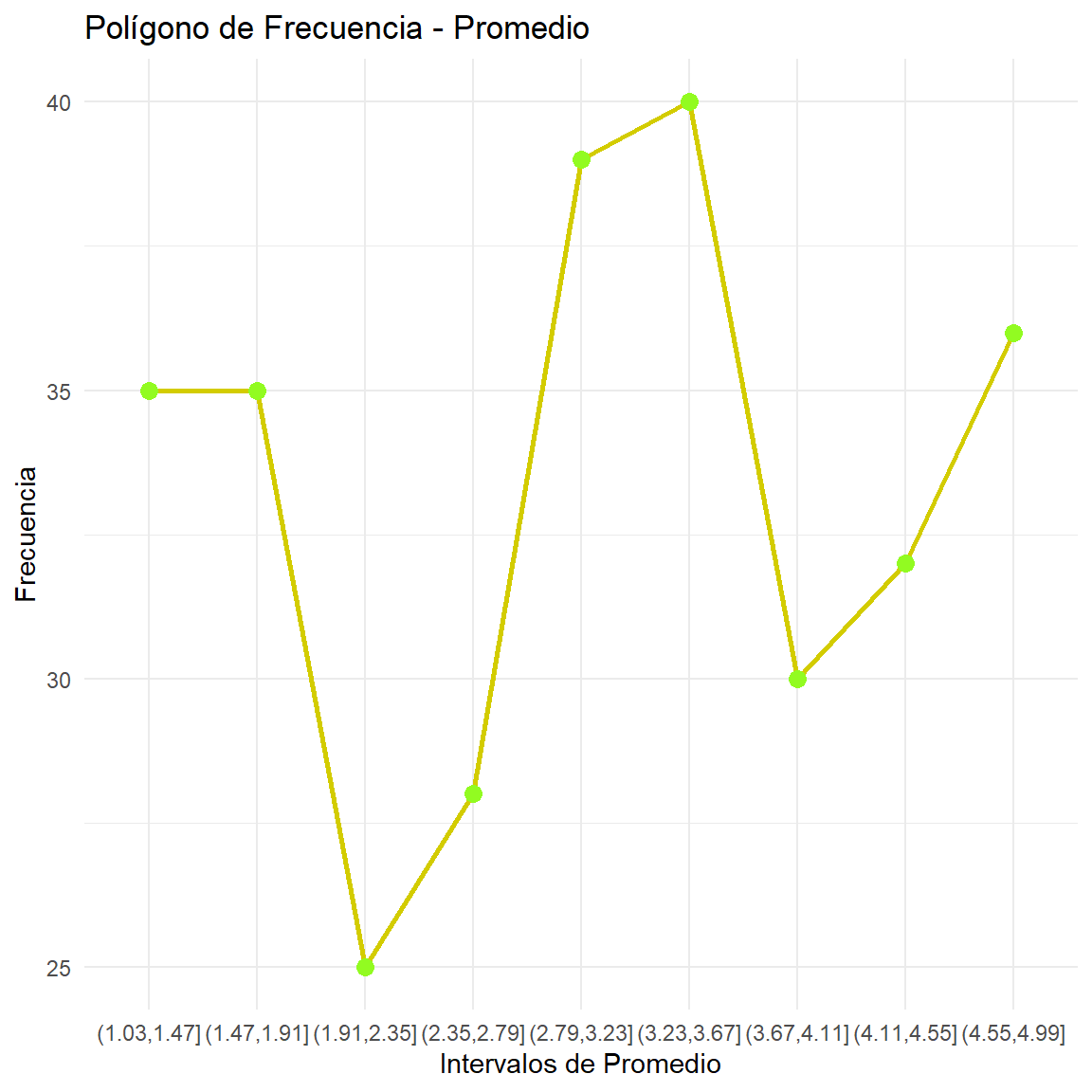
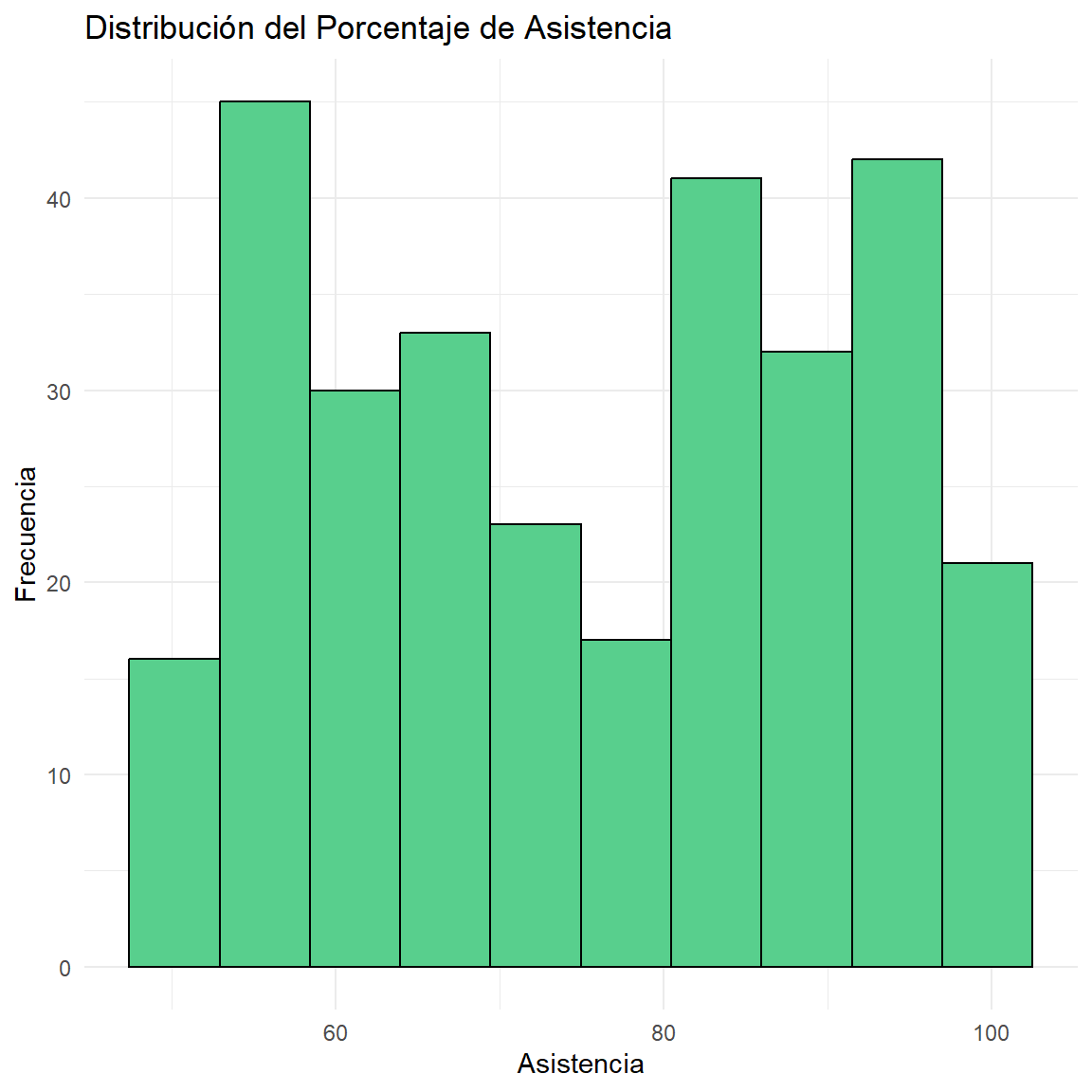
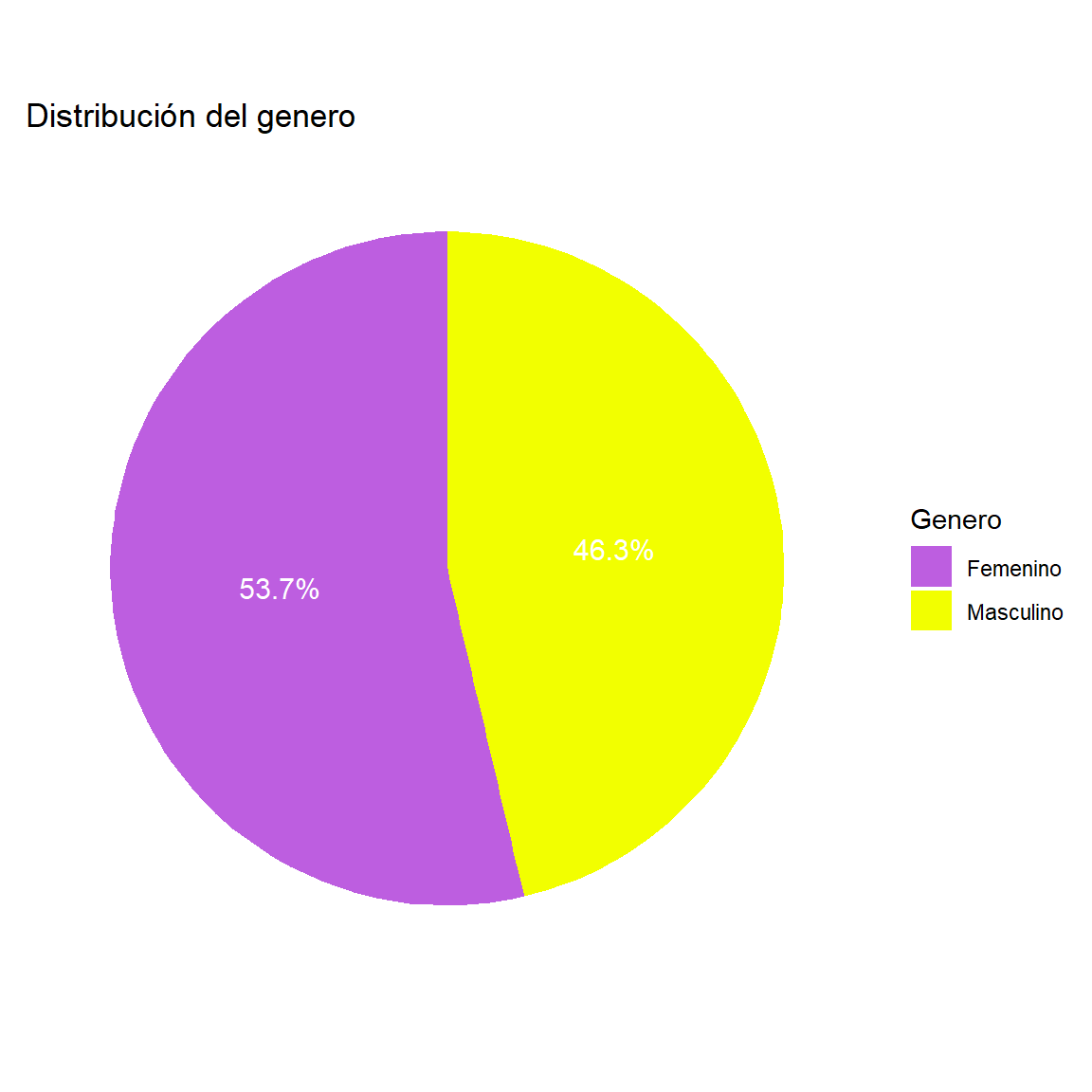Rows: 300
Columns: 10
$ ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,…
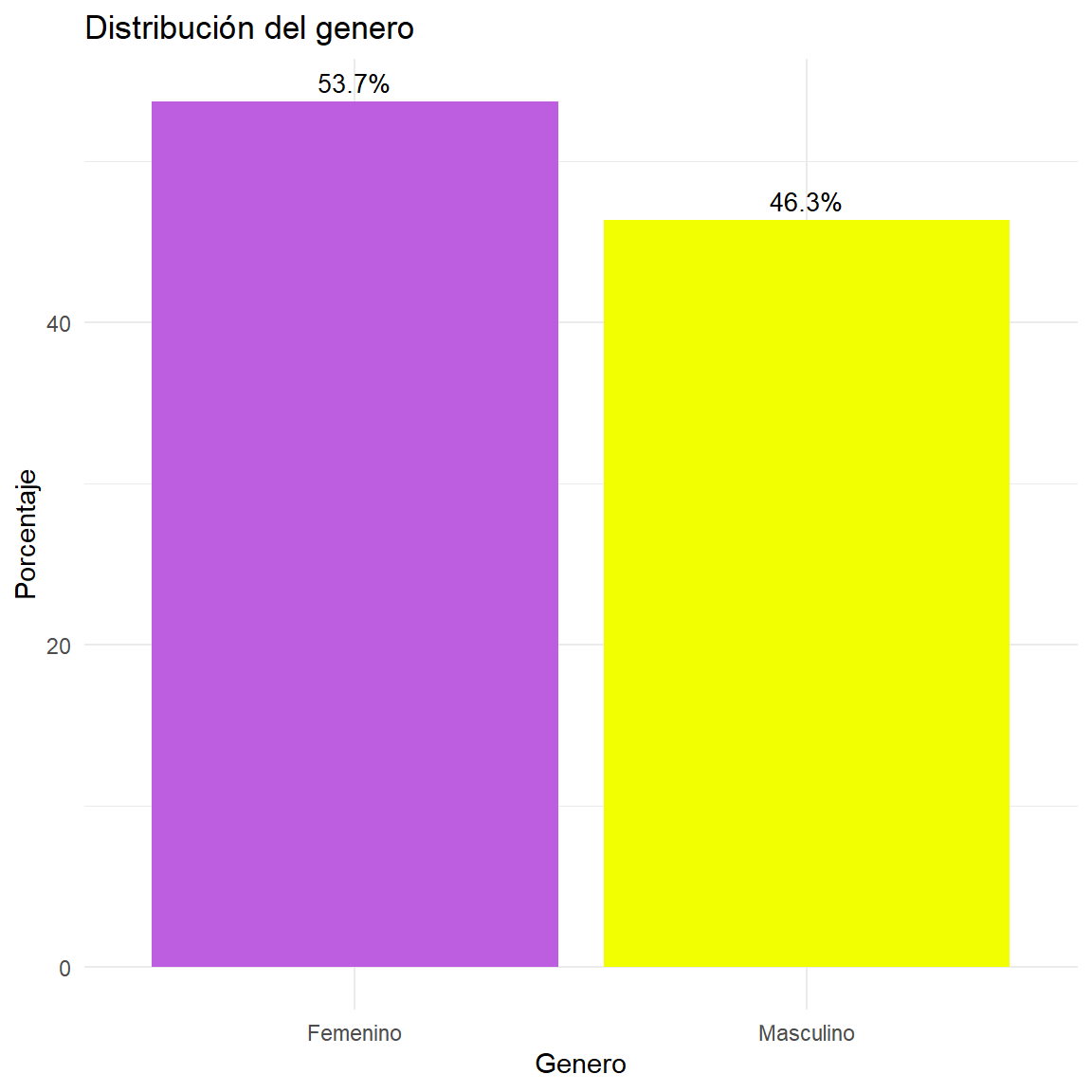
$ Genero <fct> Femenino, Femenino, Femenino, Femenino, Masculino, Mas…
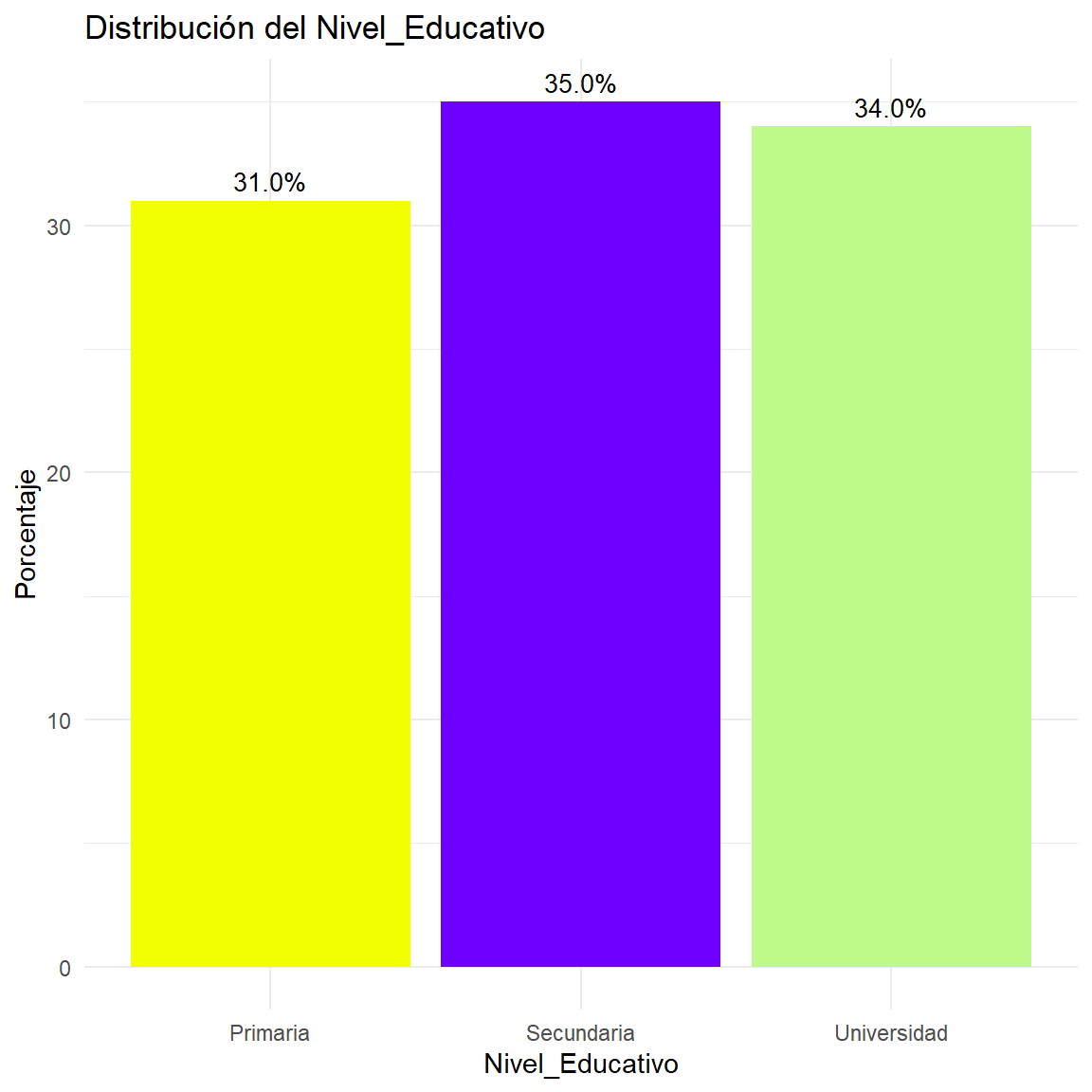
$ Nivel_Educativo <ord> Universidad, Universidad, Secundaria, Universidad, Uni…
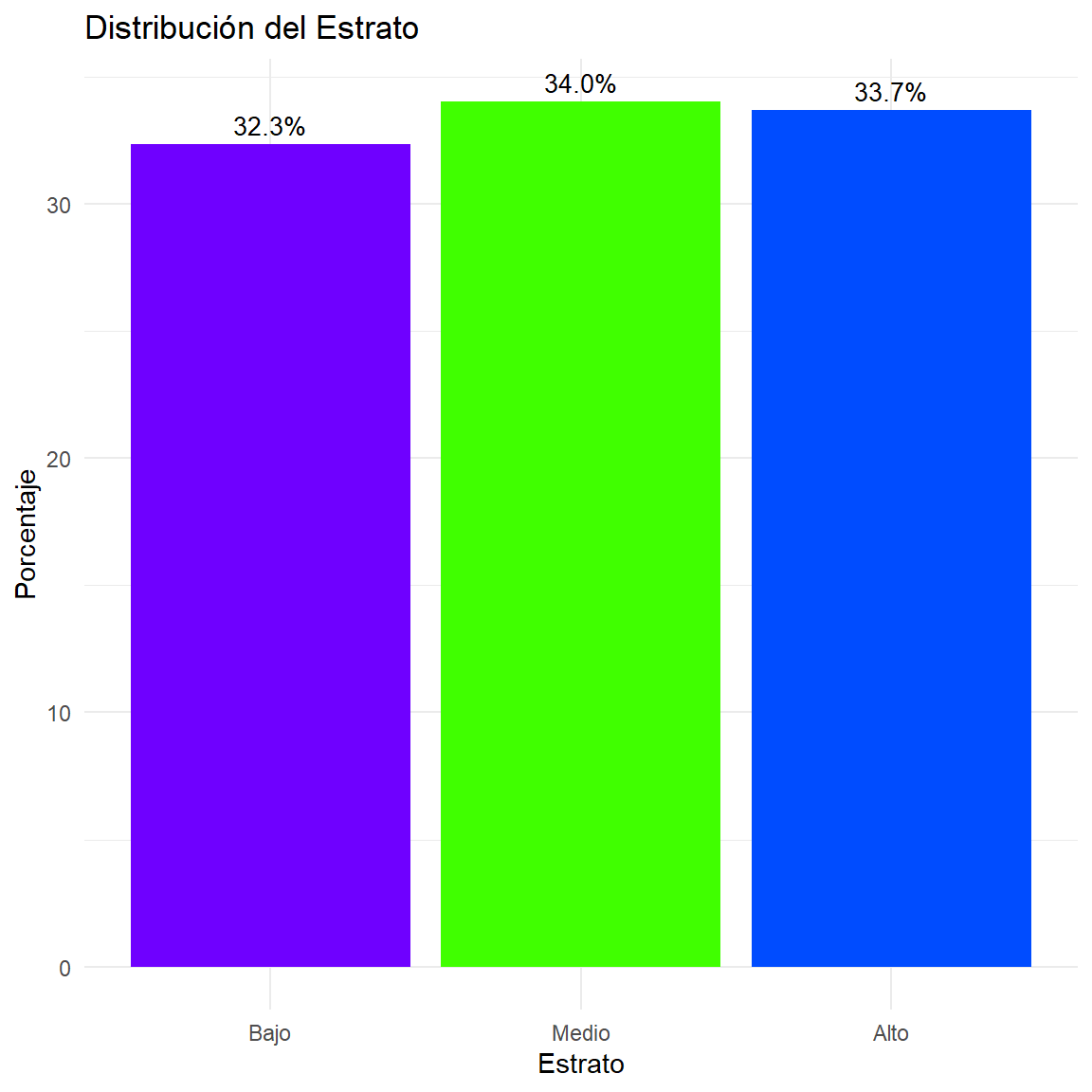
$ Estrato <ord> Alto, Bajo, Medio, Bajo, Alto, Bajo, Bajo, Medio, Medi…
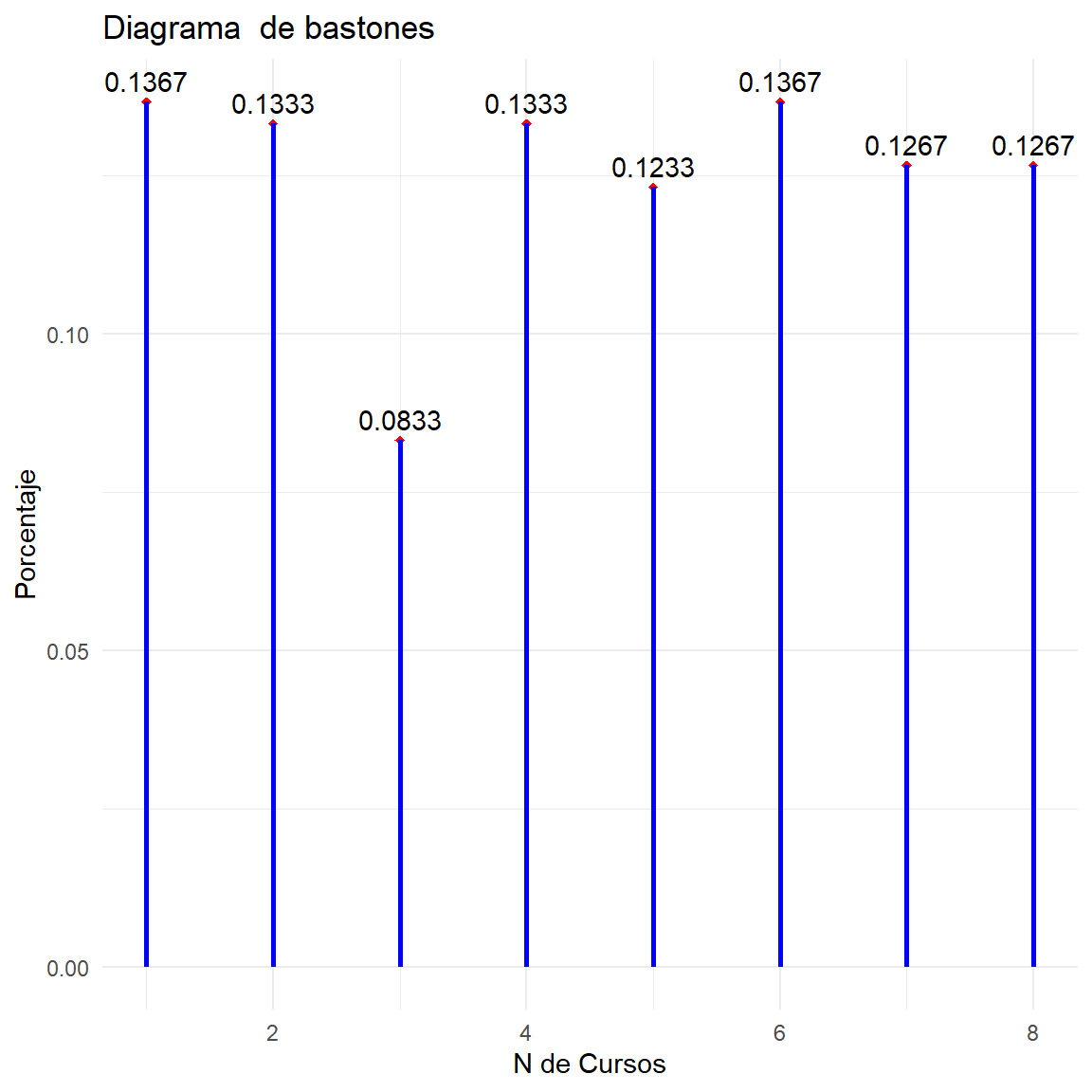
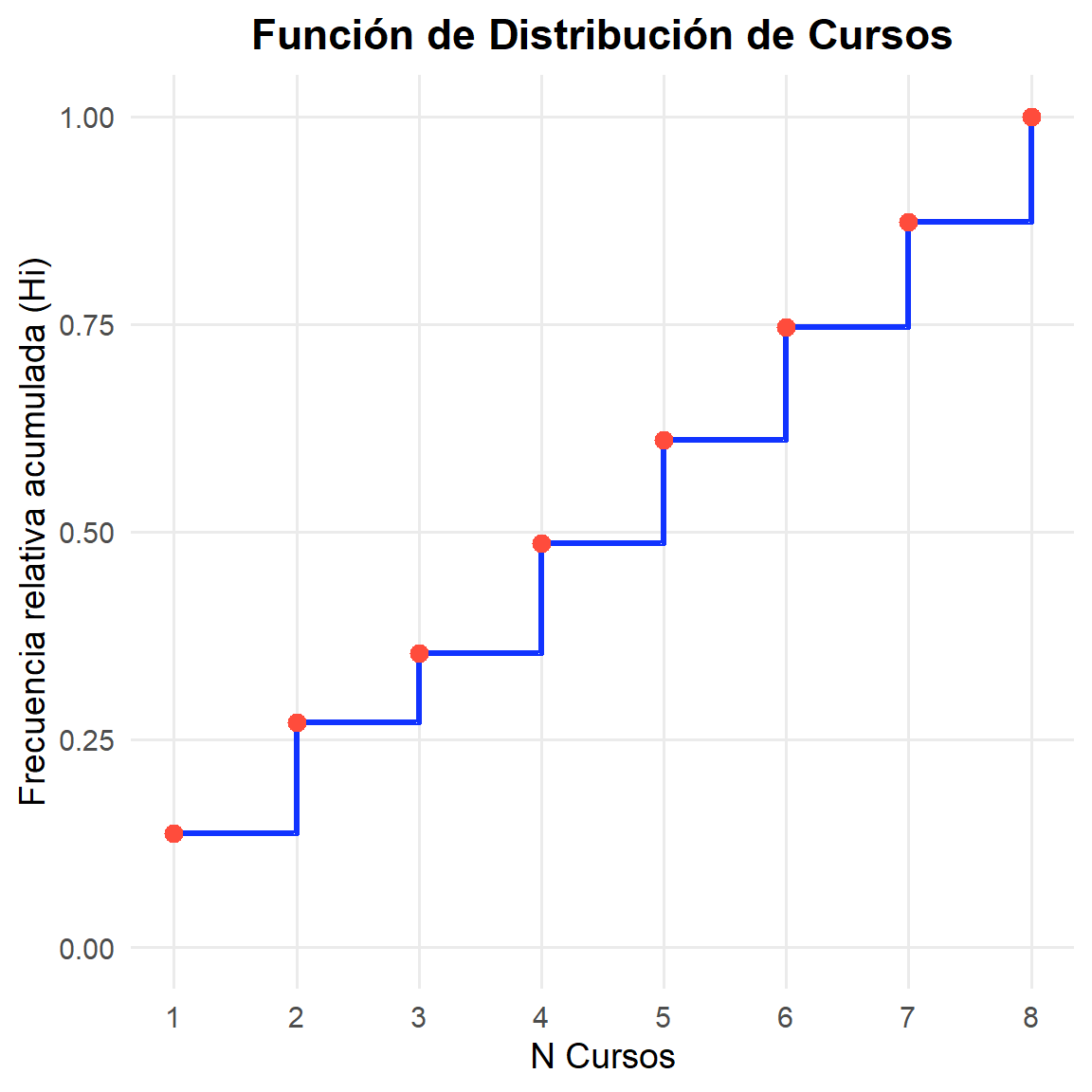
$ Cursos <int> 5, 4, 8, 6, 4, 2, 2, 6, 8, 4, 6, 2, 2, 6, 8, 5, 1, 8, …
$ Horas <dbl> 26.82, 9.05, 28.19, 17.86, 15.87, 27.63, 3.31, 14.81, …
$ Promedio <dbl> 4.37, 4.90, 1.26, 1.96, 3.60, 4.58, 1.47, 3.89, 4.65, …
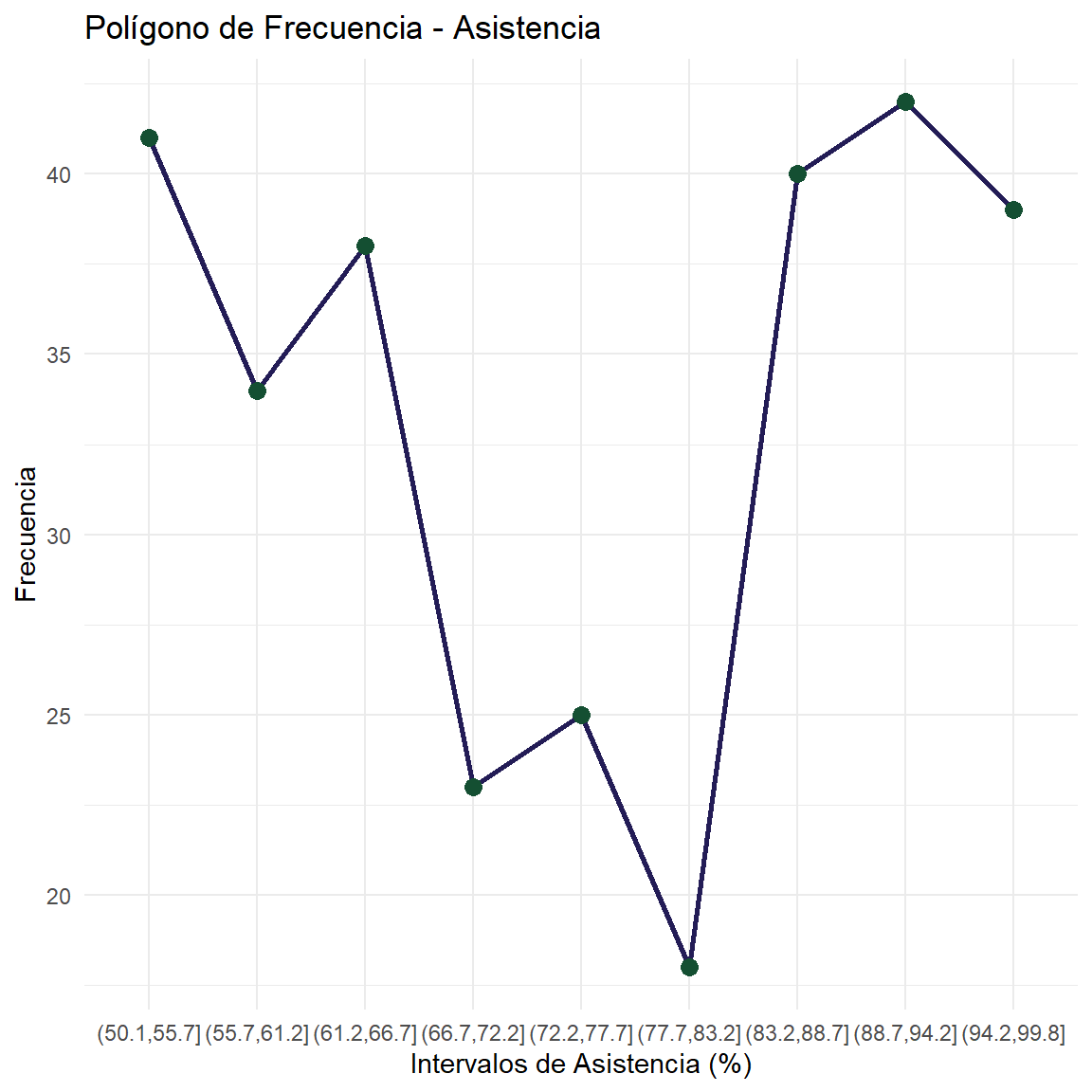
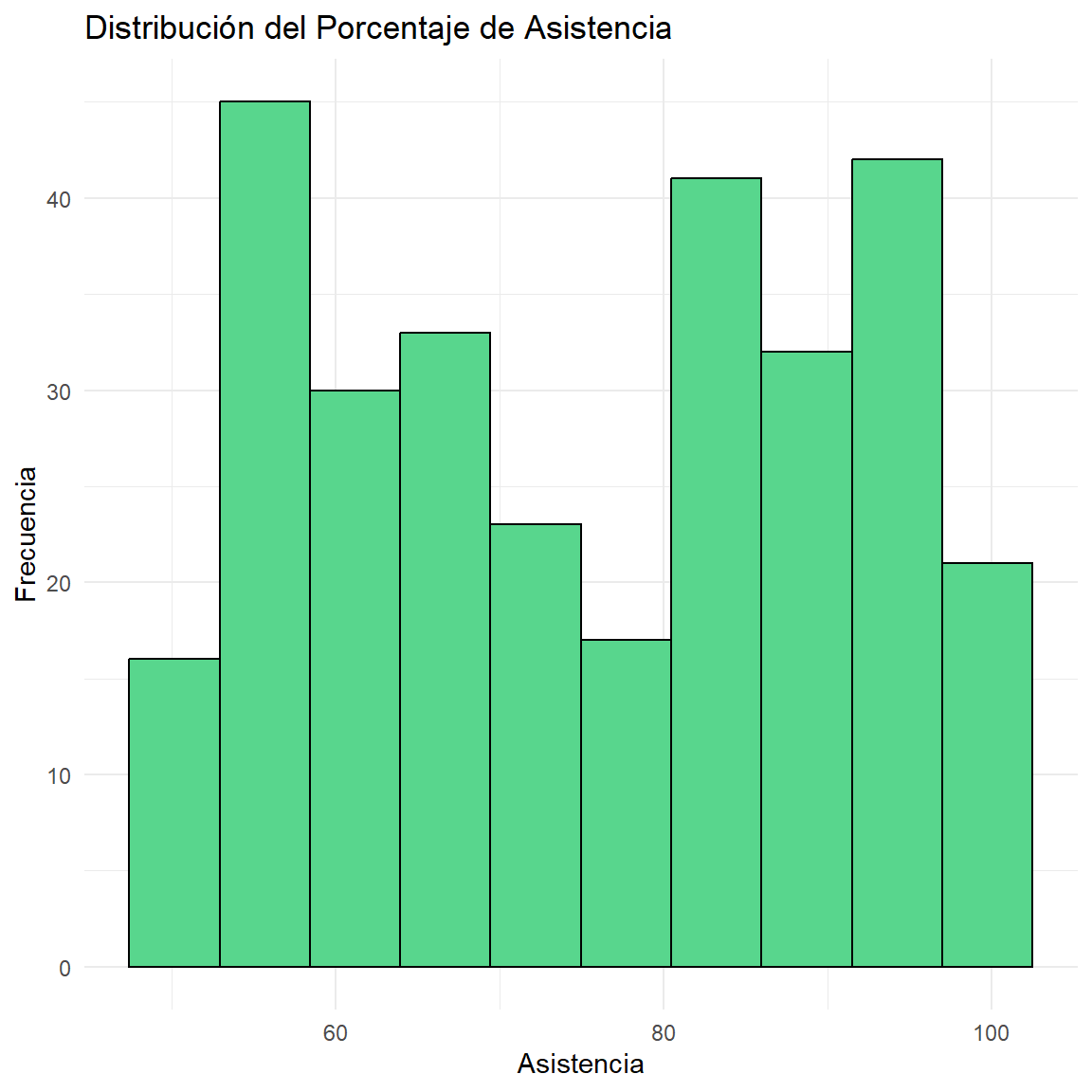
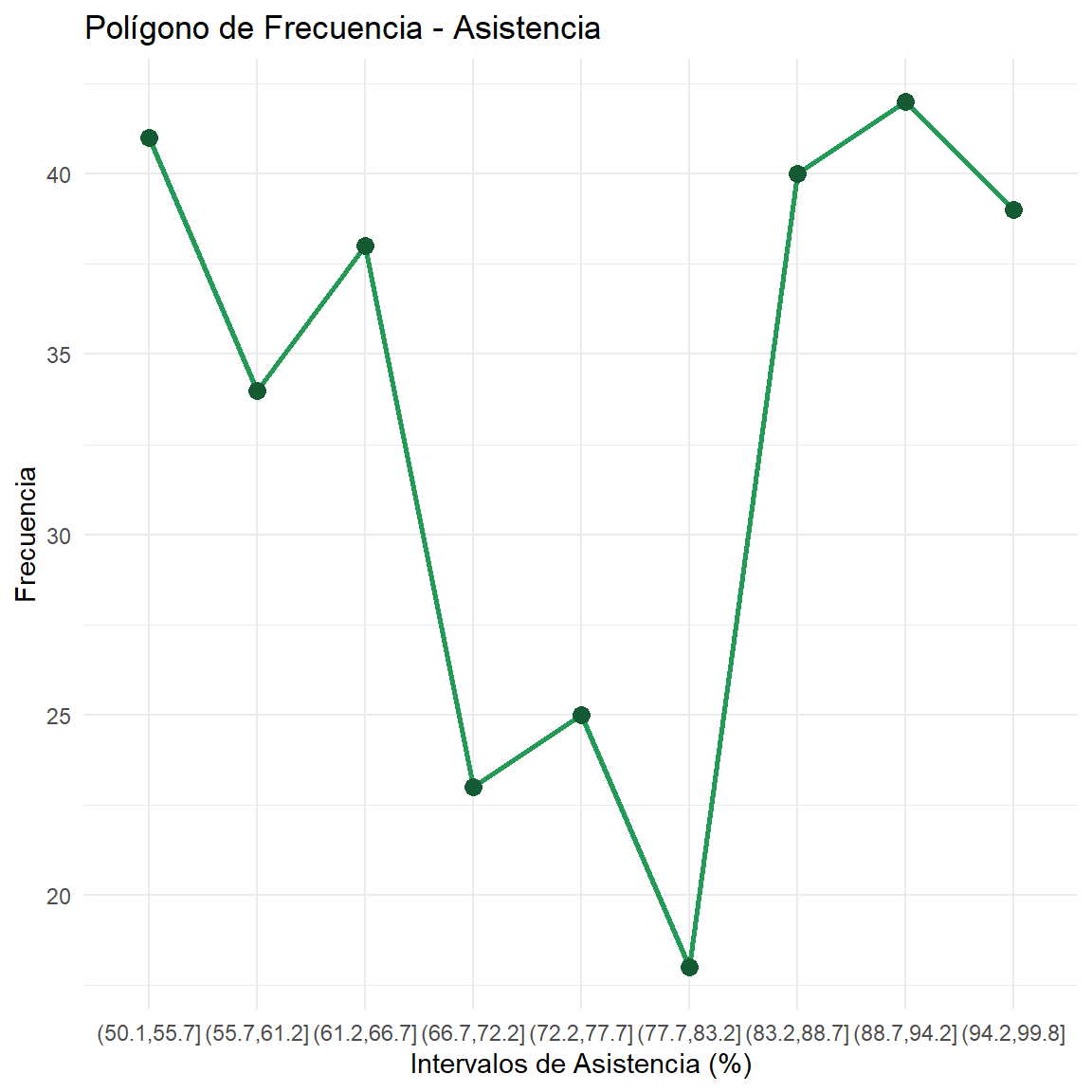
$ Asistencia <dbl> 51.29, 51.06, 92.35, 64.85, 57.01, 76.11, 84.15, 93.22…
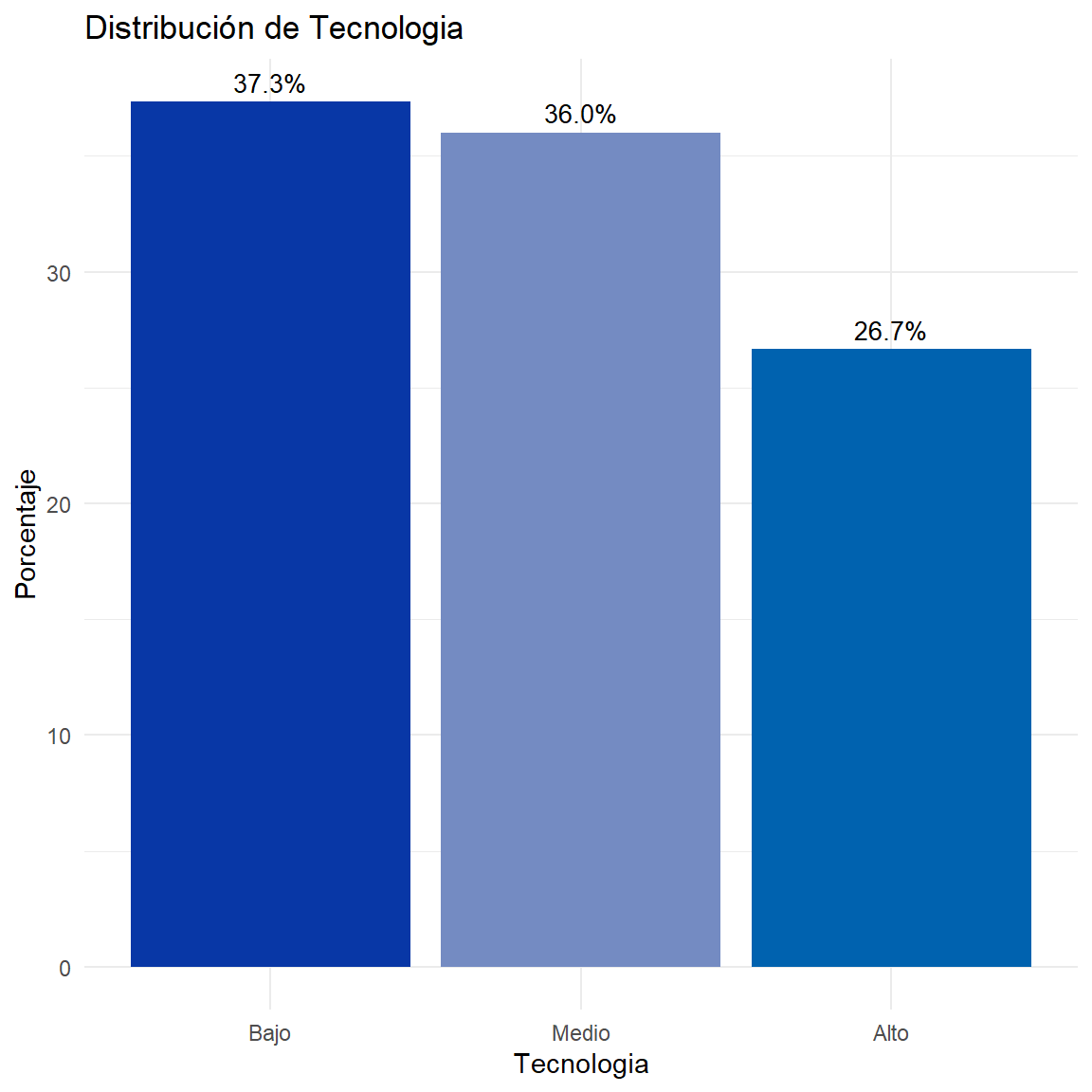
$ Tecnologia <ord> Bajo, Bajo, Bajo, Medio, Alto, Medio, Bajo, Medio, Alt…
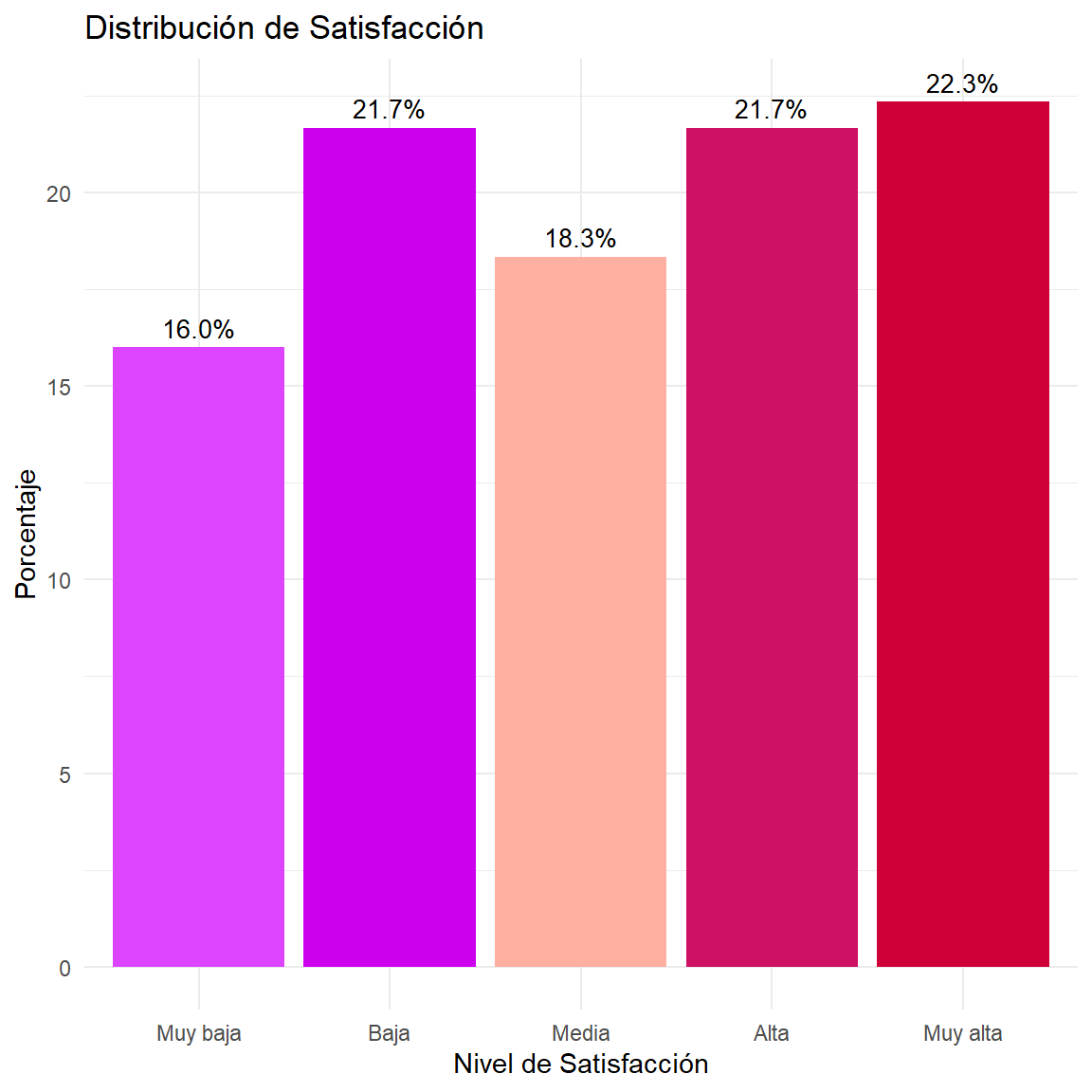
$ Satisfaccion <ord> Muy alta, Media, Muy alta, Muy alta, Muy baja, Alta, M…